目前网络上还没有成套的机器学习与深度学习的入门文档,本系列从机器学习概念开始,一步步了解人工智能。
机器学习分为两大类:监督学习与非监督学习。
监督学习
即监督学习过程,并提供学习结果校验。说白了就是需要正确的数据集用来学习和对照。
常见的线性回归和分类回归都属于监督学习的范围。具体后面讲。
非监督学习
没有明确的数据集用于对与错的训练,较为抽象。
举例子 各个网站的新闻推荐算法就是非监督学习。这个算法把所有新闻作为样本,没有对与错,你看了某类新闻后,算法给你推荐类似的新闻。这种算法没法用样本的对与错来训练,只能喂大量的数据集用于训练。
典型的,ChatGPT就是非监督学习类型。他把互联网所有东西都看一遍,自然也就学会了。
本文重点讲监督学习,而非监督学习需要在深度学习中接触。
线性回归
某地房产中介统计小区成交房价样本如下(101平的房子还没有卖出去):
| 面积(平方米) | 89 | 68 | 120 | 93 | 101 |
| 价格(万元) | 148 | 100 | 190 | 153 | ? |
已知前四套房(4个样本)的成交价格,那么第五套房应该卖多少钱比较合适呢?
线性回归是最基础的一种监督学习算法。
线性回归分为很多种 ,直线,曲线都有。本章简单讲解最基础的一维线性回归,即只有一个自变量。可以解决上面的问题。
一维线性回归需提供学习样本,算法会将样本拟合为一维线性方程:
其中,w为斜率,b为截距,在直角坐标系中为一条直线。样本为直线附近的点。
所以第五套房应该卖多少钱比较合适呢?我们需要将四个样本喂给一维线性回归算法,让其根据四个样本拟合出一条直线。进而推算出第五个房子应该卖多少钱。
接下来我们具体讲讲算法是如何拟合出一条直线的。
拟合
为了简单讲解和方便计算,一维线性回归方程中的 b ,本章默认取0,即
我们先假设,w=4。
将上面这个公式带入我们已知的样本中,面积为x,算出的价格为y。我们就可以得到四个算法算出来的价格:
| 面积x | 89 | 68 | 120 | 93 | 101 |
| 实际成交价格Y | 148 | 100 | 190 | 153 | ? |
| 算法算出来的价格y | 356 | 272 | 480 | 372 | 404 |
很显然,算出来的价格与实际价格差距过大,这证明我们的算法是错的,即w不能等于4。
那么什么样的w值才是合适的呢?如何量化我们的算法是否正确呢?如何找到合适的w值呢?
损失函数
损失函数就是一种量化算法是否正确的算法,这个算法会计算每次不同的w值下,测算结果与真实结果的差距。这个差距越小那就证明算法越正确。损失函数(Loss function,简称L)的定义如下
看不懂?我给你啰嗦明白。从右往左看,i 为编号,四个样本分别 i=1,2,3,4。f(i) 就是算法算出来的价格,而实际价格为Y(i)。他俩相减也就代表了测算结果与真实结果的差距。那么为什么要平方呢?因为相减算出来的有可能是负数,平方了之后就没有负数了,毕竟差距不可能是负的,而且平方后也相当于放大了差距,更容易看出来差距。求和的目的是为了算出所有样本的差距之和,最后乘以 1/n 是为了算出平均差距。这就是损失函数的全部定义了。如果还没看懂公式,那这段再读一遍。
梯度下降算法
损失函数是一个关于w的函数,如何找到这个函数的最小值呢,这就需要使用梯度下降法了。
梯度下降法就是用来求损失函数最小值时w对应的值。
广义上,需要应用梯度下降法来求最小值的函数,都写为 J(θ)。在本章中,θ与w意义相同, J(θ) 就是我们的损失函数L(w),后面不再赘述。
多次带入不同的w并求损失,然后画出来图像后可以得知,我们的损失函数是关于w的一元二次函数,开口向上,存在一个最低点。而最低点对应的w值就意味着此处损失最小,也就是最合适的w值。
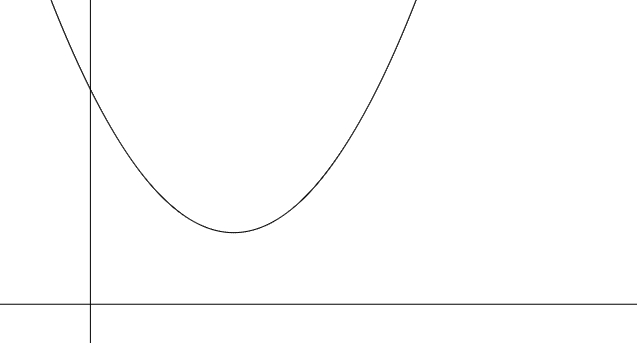
在损失函数的图像上,在某一点上,其导数有三种情况。
导数大于0则表示在该点为递增函数,所以我们需要向左移动,减小自变量,才能使函数值减小。
导数大于0则表示在该点为递减函数,所以我们需要向右移动,增大自变量,才能使函数值减小。
导数等于0则表示目前已经是函数的最低点,w取此值时损失函数值最小,也就表示此时的w算出来的拟合函数与样本数据最为接近。
所以只需要求其导数,并判断其大小,然后根据导数值决定向左移动或向右移动即可。不断地左移右移,最终找到导数为0的最低点,这就是梯度下降算法。
由于我们的回归方程是简化版,即只有一个参数w,另一个参数b被我们人为置0了,所以损失函数是一个平面一元二次方程。但实际上参数b不可能为0,所以损失函数也不再是平面的,而是一个立体的“碗形”。在三维坐标系中,x轴和y轴对应两个自变量参数w和b,而z轴则是对应的损失值。在这样的损失函数中找最小值实际上就是对“碗底”的探索。接下来我们考虑b不为0,也就是更加常见的情况。
梯度下降算法定义如下
公式解析:
还是从右往左看,θ1是我们初始的θ值,也就是我们上一章定义的w=4(别忘了θ与w意义相同)。其实际含义为:当θ1取值为4时,损失函数算出来的损失值为 J(θ1)。左侧的 ∂ / ∂θ1 表示对 J(θ1) 求关于 θ 的偏导数,也就是我们上面讲到的求导,之所以偏导是因为自变量有两个, w和b,每次求w值时就对w求偏导,求b值时就对b求偏导。求导后的值有三种情况,就是我们上面讲的大于0小于0等于0。求导后乘以左侧的 α ,这个α我们暂时先跳过,暂时取α = 1,继续往左看。用最开始的θ1减去我们算完的导数结果,就能得到新的θ值,即θ2,此时有三种情况。
当θ1处的导数大于0时,新的θ2 = θ1 - 一个正数 。结果就是θ2要比θ1小。
当θ1处的导数小于0时,新的θ2 = θ1 - 一个负数 。结果就是θ2要比θ1大。
当θ1处的导数等于于0时,新的θ2 = θ1 。
这也就实现了梯度下降算法,即导数大于0时向左移动,减小自变量θ,导数小于0时向右移动,增大自变量θ。然后我们把算出来的θ2,再次带入公式,求出θ3,然后继续带入……。
多次运用梯度下降算法,直到新的θ值不再变化,也就完成了梯度下降算法,最终使损失函数 L(w) 的值无限趋近于最低点。我们也就找到了本章开头所说的 “损失函数最小值时w对应的值”。
此处数学推理过程,略,由于较为复杂后面我会单独开一篇讲一下这个偏导数的算法和计算过程,来帮大家回忆一下高等数学,当然本章只要理解概念就好不必非要死磕数学。
在每次梯度下降时,要分别求w和b的新值。此处应注意先后顺序,不要先求w然后再求b,因为先求得的w会影响到对b求偏导。所以应该同时进行,或者求b偏导时用w的初始值。
此处我直接给出计算结果,即θ值为1.6时,梯度下降算法不再继续下降,损失函数取得了最小值,此时拟合函数为
学习率
可以看到每次θ变化时都会乘以这个 α ,如果学习率比较大,那么它与J(w)的偏导数的乘积也就比较大,新的θ值相较于老的也就变得比较多。所以学习率越大,梯度下降法里面的“梯度”也就越大,损失函数也就越快的下降到最低点。但步子大了也不行。学习率过大会导致梯度下降算法无法收敛,最终结果损失函数会逐步扩大,发散了。学习率从小往大选择,一般从0.001开始。依次三倍放大。即:
0.001→0.003→0.01→0.03→0.1→0.3→1→3→10→30→100……
特征缩放
在多个自变量参数共同影响的模型中,每个参数对于结果的权重是不同的,这会使得损失函数的三维图形,也就是那个“碗”会变得很扁,不方便梯度下降算法寻找最低点。为了抹平这种差距,需要特征缩放,使碗尽可能圆。这就需要将每个自变量乘以系数进行扩大或缩小,这就是特征缩放。一般将参数缩放至[-1,1]之间。当然如果特征值本身就不大,也没必要缩放。
要选择正确的特征用于训练AI,对于房价来说,面积,楼层都是有效的特征。且面积的权重最大。
多项式回归
非线性回归,需要拟合出一条曲线而非直线。比如一元二次方程、一元三次方程。三次方会使曲线更加陡峭,而二分之一次方则会更平坦。具体选择哪个要根据实际样本来决定。
逻辑回归
输出值不是0就是1。比如根据一张肿瘤图片来判断该肿瘤是恶性的还是良性的。
这种数据无法用线性函数来表示,我们可以考虑如下公式
其图像如下,在z值为3附近,f(x)的值大概为1
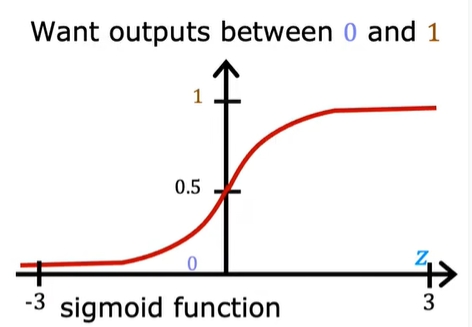
考虑简单情况,z为线性,即
这样我们就有了关于x的模型函数了
这就是逻辑回归模型了。对于上面的例子 x 表示肿瘤大小,那么 f(x)就是是否为恶性肿瘤的概率了。当f(x)>0.5,也就是z大于零时我们认为肿瘤为恶性。实际上自变量x可能有多个,我们统一用向量表示,那么w的意义就是每个特征值的权重。
决策边界
如下图,有x1和x2两个特征值,蓝色为良性,红色为恶性
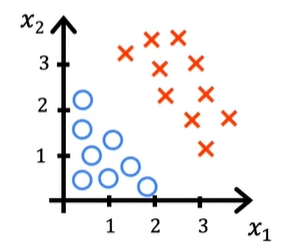
那么对应的函数g(z)我们可以这么写,自变量有两个
对应的f(x)如下
其中矩阵x为x1和x2的合集
再看下面的例子
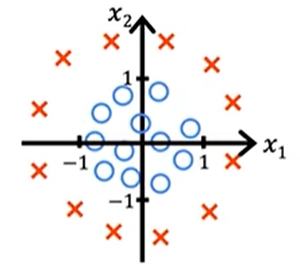
对应的函数g(z)我们可以这么写
对应的f(x)略
其他更复杂的决策边界,也就是g(z)函数更复杂而已,比如
具体的决策边界要依据实际数据来选择或定义
成本函数
在多个特征值的逻辑回归中,回归模型带入之前讲过的损失函数,来计算最优解w。
但是和线性回归不同,线性回归的损失函数是一个碗型,我们可以梯度下降寻找最低点,但逻辑回归的损失函数是凹凸不平的碗,无法直接使用梯度下降。所以在逻辑回归中,我们放弃之前的损失函数定义。换新的。
逻辑回归的损失函数分为两种情况,这里我就不解释了,图像画出来就明白了。不得不说这公式很妙,不知道是谁想出来的。
这样的损失函数是光滑的,不会凹凸不平,就可以使用梯度下降了。
更妙的来了,上面这个损失函数不是两行吗,让我们简化一下。
当Y(i)=0的时候,公式左半边为0,只有右半边生效。而当Y(i)=1的时候,公式右半边为0,只有左半边生效。这样就把两行公式简化成一行了。
成本函数其实就是损失函数的值,求和,再平均,就是成本函数了。
这个成本函数可用梯度下降法进行优化,降低模型成本。分别对w和b进行优化
对w和b求偏导即可,展开如下,要注意同步更新,即新的w值不要影响b的偏导计算。
过拟合问题
模型训练出的函数过度拟合数据集,损失函数非常低,导致模型无法预测其他值。
欠拟合则相反,函数与模型不符,或者模型选择不合适,一般很少有直线的数据集,所以用一元一次函数做模型大多数都会欠拟合。
过拟合的解决方法有很多,比如增加数据集的量,或者减少特征值。对于房价,周边的咖啡馆数量显然不算什么好的特征值,可以去掉。
第三个办法叫正则化
正则化就是降低部分相关性很小的特征项对模型的影响。
当我们在不知道哪个特征是重要的或者不重要的时候,我们无法对特征根据不重要性进行删除,这时应该使用正则化。而对于我们可以自主判断出哪些是不重要的特征,我们当然可以选择直接去除那些不重要的特征。
对于线性回归,其损失函数加上正则化参数如下
公式左侧没变,还是它的成本函数。但右侧加了一部分,这里讲一下右侧。首先是w进行平方,相当于放大了每个特征值的w对成本的影响。然后求和,再乘以λ,最后除以2n,这里除以2n是为了和左侧保持一致,这样的话选择λ能更加容易。
λ是正则化参数,和学习率一样,需要我们配置。公式可以看出,λ越大则w对成本的影响就越大。在实际中我们只对各种w做惩罚,而不对b做惩罚。因为w才会影响每个参数的权重,b影响不大。不过也有人把b加到成本函数中,本文不做参考。
如果λ取值过小,极端点为0,那么相当于你没有引入正则化参数,得到的最终曲线则会是过度拟合的。但如果你的λ取值很大,比如一个小目标,那也就意味着在成本函数中右侧权重极高,唯一使成本降下来的方法那就是让所有w都趋近于0,这样就会欠拟合。λ的选择很重要,决定了最终结果的拟合程度。
对于线性回归,使用梯度下降法求偏导后的结果如下
正则化不会影响b,所以b的成本函数没有变化
对于逻辑回归,正则化与线性回归类似,此处不做详解。